One Founder Running Jira, Confluence, GitHub, and AWS with AI Agents
Enterprise tools and AI agents are finally aligning in a way that makes the overhead disappear. Here's how the toolchain actually works.
Here's what I'm attempting: running a multi-tenant SaaS backend with full enterprise governance — epics, stories, sub-tasks, PRDs, architecture docs, CI/CD pipelines, deployment auth — alone.
Not "mostly alone." Not "with good tooling." Actually alone, without cutting corners on rigor.
The obvious reaction is that this is either naive or reckless. Maybe both. But I'm starting to think enterprise tools and AI agents are aligning in a way that could make the overhead disappear — that the tooling which would have been a 40% time sink might actually enable the work. I want to explain the setup I'm trying and why, because I think the reasoning matters more than the tools themselves.
Why enterprise tools for a solo founder
The obvious pushback is: "Just use a text file and a repo. Don't overcomplicate it."
That advice assumes tooling is a cost you endure for alignment across a team. And for teams, it often is overhead. But the setup I'm exploring isn't designed for alignment across people. It's designed for consistency across AI agent sessions.
Here's the problem I keep running into. You ask an AI agent to implement a feature. It produces code. You review it. Three days later, you ask another agent — or the same one in a new context — to work in the same area. It writes something that contradicts the first implementation. Different patterns. Different assumptions about error handling. Different naming conventions. This isn't because agents are dumb. It's because they don't have persistent working memory. Each session starts at zero unless you explicitly seed it with context.
Add that up across weeks and you've got a real problem. You're manually assembling context before every session. Agent output is inconsistent because the context each one received was subtly different. You spend more time normalising output than you save on execution. My hypothesis is that the governance infrastructure — the tickets, the docs, the architecture diagrams, the acceptance criteria — isn't bureaucracy. It's the persistent working memory that could make agent execution reliable.
The toolchain
I'm setting up five interconnected systems. Jira handles the operational backbone: epics for architectural components, stories with acceptance criteria mapped to the PRD, and sub-tasks scoped to single agent sessions — typically 45 minutes to 2 hours of work. The sub-task is the critical level. Small enough that one agent can hold the full context in a single conversation. Large enough to be meaningfully complete.
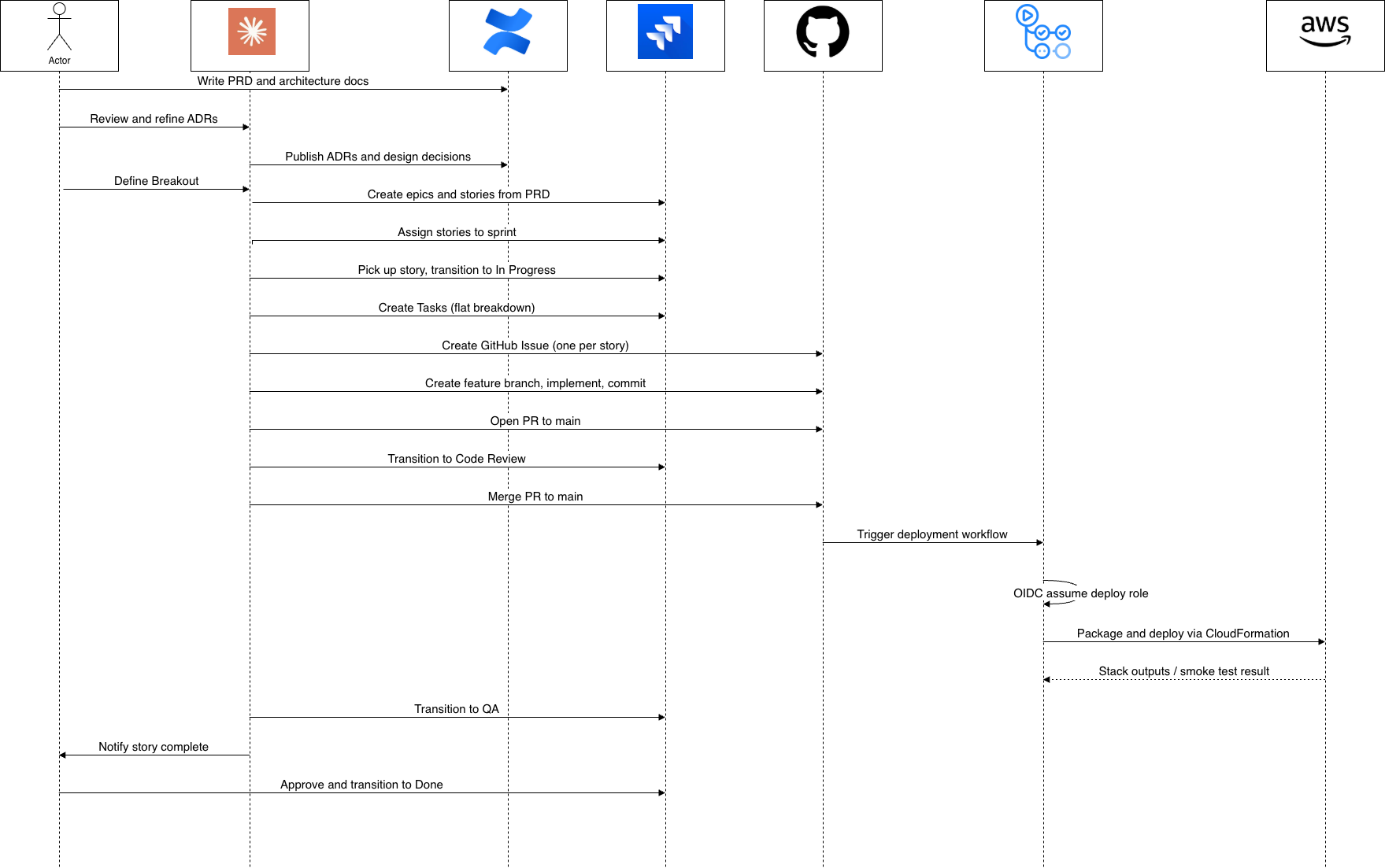
Confluence is where the reasoning lives. Jira tells you what was decided; Confluence should explain why. The PRD describes the product vision and acceptance criteria for every feature. The architecture pages explain system design choices — how multi-tenancy is enforced, why DynamoDB over RDS, what tradeoffs we're making on consistency models. The theory is that agents are pattern-matching machines. If you don't document your design decisions, they'll infer patterns from code. Inferred patterns are fragile — sometimes wrong, often inconsistent. Explicit documentation should let agents understand the intent behind a pattern, not just the pattern itself. That's the bet, anyway.
GitHub handles version control and deployment with one notable addition: OIDC deployment authentication. Instead of storing AWS credentials, the GitHub Actions workflow uses OpenID Connect to assume a role directly. No long-lived secrets anywhere. Infrastructure is described in a mix of SAM templates and Terraform depending on the resource — SAM for the serverless application stack, Terraform for the broader account-level setup. This is one area where I'm deliberately in the middle of the loop. Agents can write code, open PRs, and push to the repo, but nothing gets deployed without my authorisation. The OIDC authentication means every deployment runs through a role I control, scoped to exactly the permissions that workflow needs. No agent, no CI job, no automated process can spin up resources I haven't approved. That's not just a governance preference — it's how you avoid waking up to a surprise AWS bill because an agent decided it needed a new DynamoDB table with on-demand capacity.
AWS runs the actual workload — serverless-first with API Gateway, Lambda, DynamoDB, and EventBridge. No persistent containers, no scaling decisions. Lambda cold starts are around 200ms for Python, which is fine for backend APIs.
Four systems. The goal is zero manual synchronisation between them. One person.
The connective tissue
The thing I'm banking on to make all of this work together is MCP — the Model Context Protocol. It's a standard that lets AI agents interact with external systems through authenticated connectors. The agent itself never touches APIs directly. It doesn't handle tokens. It doesn't construct OAuth flows or manage credentials. All of that happens at the connector level.
Think of it like this: instead of giving an AI agent a database connection string, you give it a query_database function. The function handles authentication and connection pooling. The agent just calls it.
So when an agent needs to search Jira for sub-tasks in the active sprint, it goes through the Atlassian MCP connector. When it needs to create a branch and commit code, it goes through the GitHub connector. In every case, the connector owns the credentials. The agent never sees them. Permissions are scoped and enforced at the connector level — an agent can open PRs but can't delete repos.
The security model is clean in theory, and the standardisation means adding a new system should follow the same pattern every time. Connector handles auth. Agent gets a well-defined interface. Whether this holds up under real load is something I'll find out.
What a session actually looks like
Here's what I'm aiming for. You point the agent at a sub-task. It queries Jira for the active sprint, reads the acceptance criteria, follows the link to the parent story, opens Confluence to read the relevant PRD sections and architecture docs. It searches the GitHub repo for similar features already implemented — what patterns are in use, what the test structure looks like, how errors are handled.
Then it creates a feature branch, implements the feature following the patterns it found, writes tests, commits with a message referencing the ticket, and opens a pull request. The CI pipeline runs. If it passes, the agent transitions the Jira ticket to "In Review."
That's the theory. The entire workflow — context gathering, implementation, testing, PR creation, ticket transition — in one continuous conversation. No tab-switching. No manually copying context between systems. The agent reads what it needs and writes where it needs to. Systems stay synchronised because the agent is the single source of mutation.
My part comes next: reviewing the PR. This is where human judgment still matters entirely. I'm checking whether the implementation matches the intent, whether there are edge cases the acceptance criteria didn't mention, whether the error handling is what I actually want, whether naming choices are consistent with the domain language. I approve or leave comments, and the next session picks it up. Early results are promising, but I'm still learning where the edges are.