My Multi-IDP Authentication
Your first customer uses Auth0. Your second uses Google Workspace. Your third insists on Microsoft Entra. Here's how one authorizer handles all of them.
You're building a B2B SaaS platform. Your first customer uses Auth0. Your second uses Google Workspace. Your third insists on Microsoft Entra. They all send JWTs to your API, but the JWTs look completely different. The issuer is different. The claim structure is different. Even the way roles are encoded is different.
How do you handle this with one API Gateway and one authorizer function?
This is the problem we solved in Porth (My project name for this component), and I want to walk you through how — because the answer isn't what most people reach for first.
The problem, made concrete
Here's a JWT from Auth0:
iss: https://acme.auth0.com/
sub: auth0|123456
roles: ["admin", "viewer"]
org_id: acme
And one from Google Workspace:
iss: https://accounts.google.com
sub: 114567890123456789
groups: ["engineers@acme.com", "admins@acme.com"]
hd: acme.com
And Microsoft Entra:
iss: https://login.microsoftonline.com/tenant-id/v2.0
sub: 98765432-1234-5678-abcd-ef1234567890
roles: ["admin", "viewer"]
oid: 98765432-1234-5678-abcd-ef1234567890
Your API needs the same three things from all of them: org_id, tenant_id, and the user's roles. Same three outputs. Three completely different shapes going in.
The instinct is to branch on the issuer — if iss.includes("auth0") do this, if iss.includes("google") do that. You end up with one fat authorizer full of conditional logic, or three separate ones. Either way, adding a fourth IdP means writing more code.
We took a different approach: pre-compiled claim mappings.
How it hangs together
Before getting into the detail, here's how the pieces fit logically:
The key thing to notice is that all the provider-specific logic lives in the configuration layer, not in code. The authorizer itself is completely generic — it doesn't know or care whether it's talking to Auth0 or Entra. It just follows the mappings.
How the authorizer actually works
When a request arrives with a JWT, the first thing we do is crack it open without verifying anything. We just read the iss claim to figure out which identity provider issued it. We don't trust the token yet — we just need to know who to ask about the signature.
That issuer URL is a key into a cache of IdP configurations that we load from DynamoDB on cold start and keep in memory. One lookup and we know everything about this provider: the JWKS endpoint, the expected audience, and crucially, the claim mappings we need to apply. The cache refreshes in the background every fifteen minutes, so configuration changes propagate without redeployment.
Next we validate the signature. The JWKS (the provider's signing keys) are also cached in memory with a one-hour TTL. In the happy path, signature validation is a local crypto operation — no network calls. If we hit a key we don't recognise, we refresh the JWKS in the background and retry. This handles key rotation gracefully without blocking the request.
Then comes the interesting part: extracting claims. Instead of writing conditional logic per provider, we run pre-compiled mapping operations — I'll explain how these work in a moment, but the short version is that each IdP has a set of typed transforms stored alongside its configuration that know how to pull the right values out of whatever shape the JWT happens to be. The authorizer just executes them in sequence.
After mapping, we check whether we actually got what we need — org_id, tenant_id, and roles. If any of those can't be derived, we reject with a 403. Better to fail closed than let a request through with incomplete identity context. If everything checks out, we return an Allow policy and inject the mapped claims into the request context so every downstream Lambda can read them.
API Gateway caches the authorizer result for about five minutes, so the same JWT won't even invoke the function again on subsequent requests. The whole thing — decode, lookup, validate, map, check, return — runs in microseconds on a warm invocation.
Why pre-compiled mappings matter
This is the part worth dwelling on, because it's the design choice that makes the whole system extensible.
Different providers structure claims differently, and not just in obvious ways. Auth0 gives you a roles array. Okta gives you groups. Google gives you groups too, but they're email addresses. Microsoft gives you roles, but sometimes as an array and sometimes as a string. Some providers nest claims in custom namespaces. Some use different field names for the same concept depending on their configuration.
Rather than handling all of this at request time — reading the shape, deciding what extraction logic to apply, executing it — we push that work to configuration time. When you add a new IdP to Porth, you define a set of typed extraction functions for each attribute you need. The operations are all simple string manipulations: direct copy, concatenation, coalesce (try A then fall back to B), split on delimiter, case normalisation, template strings. For Auth0, getting the org_id might just be a direct copy. For Google Workspace, it's a split on the hosted domain claim to extract "acme" from "acme.com". For Entra, it might be a concatenation of the object ID and the app ID.
One deliberate choice: no regex. It's tempting to reach for regular expressions when you're doing string extraction, but regex is slow at runtime and hard to reason about when it's stored as configuration. Typed operations are predictable, fast, and you can look at a mapping config and immediately understand what it does. Flexibility wasn't the constraint — speed and auditability were.
These operations are compiled ahead of time and stored with a SHA256 integrity hash, so there's nothing to interpret at request time. The authorizer just walks the sequence. No parsing, no reflection, no decision tree. The mapping is the logic, and it was resolved before the first request ever arrived.
Here's how the mapping engine breaks down internally:
The practical upside is that adding a new identity provider is a configuration change, not a code change. You create an IdP record with the issuer URL, the expected audience, the JWKS endpoint, and the claim mappings. Push it to DynamoDB. On the next request from that provider, the authorizer picks it up. No redeployment, no code review, no downtime. Ten minutes, maybe.
The core idea is simple: don't branch on provider identity at runtime. Pre-compile your extraction logic, cache aggressively, and let the authorizer do what it does best — verify the signature and apply the mappings. Everything else is just configuration.
How it all sits together
So far I've been talking about the authorizer in isolation, but it's one piece of a larger component. Porth is built on FastAPI running across three Lambdas behind an API Gateway:
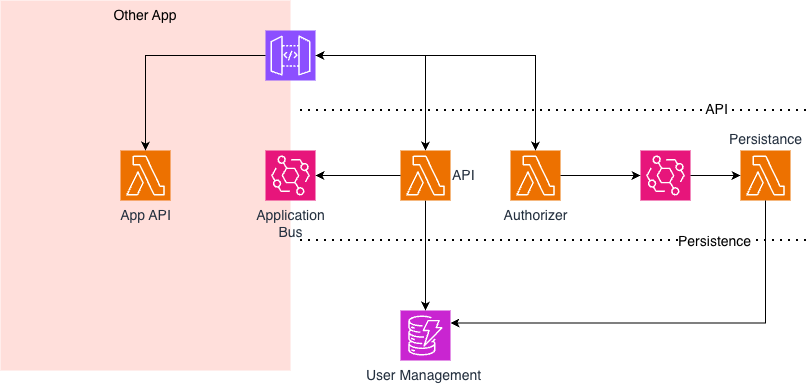
The authorizer Lambda is the one we've been talking about — it validates JWTs and runs the claim mappings. But there's a design choice worth calling out. When the authorizer sees a user for the first time, it doesn't write to DynamoDB synchronously. That would add a database write to the critical path of every first request, and the whole point of the caching strategy is to keep authorizer latency as low as possible. Instead, it fires a new-user event onto an EventBridge bus. A separate event handler Lambda picks that up and persists the user record. The authorizer stays fast; the user gets created eventually-consistently in the background.
The API Lambda is a FastAPI application that handles the management side of things — CRUD operations against DynamoDB for IdP configurations, users, tenants, and roles. When something changes on the user management side, the API Lambda publishes an event onto a second EventBridge bus. This is how Porth talks to the application sitting on top of it. The consuming application subscribes to that bus and reacts to user provisioning, role changes, deprovisioning — whatever it needs. Porth doesn't need to know anything about the consumer. It just publishes the event and moves on.
This separation keeps Porth clean as a reusable component. The authorizer is purely about authentication and claim normalisation. The API Lambda is purely about configuration and user management. And EventBridge handles the glue between them and the outside world, without either Lambda needing to know about the other.